2025年9月から同社に入社しています、VTRyo です。一週間と少し経過しました。
だんだん慣れてくると何が他社と異なるかわからなくなってきますので、まだ新鮮なうちにTopotalの日常を紹介していこうと思います。
ちなみにこのTシャツは入社とともに自宅に発送されます。
Topotalとは
Topotalは「事業成長に伴う技術課題をSREによって解決する組織」です。在籍する社員のほとんどがSREで構成されており、お客様のサービスに対してSRE as a Serviceを提供しています。
また、WaroomというインシデントマネジメントのSaaS も展開しています。
topotal.com
ギルド構造で働くTopotalの日常
分散型チームでよく課題となる「情報共有の難しさ」や「知識の属人化」といった問題に対して、Topotalでは積極的に取り組む工夫が実装されています。
バディ制による協力体制
SRE as a Serviceにおけるお客様のご支援については、必ず2名以上がアサイ ンされるようになっています。
ひとりで担当するということはなく、互いに協力しながら社内のSlackやGather(バーチャルオフィス)を使って相談しながら進めています。
この体制により、知識の属人化を防ぎ、品質の向上と継続性を担保しています。
またどちらかが不在となっていても、お互いに助け合いながら進められる安心感もまた精神的に重要です。
ノウハウの自動収集と共有
組織にとって情報のサイロ化は常に課題になります。DevOpsを体現するSREは、この問題を解決すべく頭を悩ませます。
Topotalにおいては、まだ少数精鋭組織という前提もありますが次のようなことが実施されています。
定期的なLT会の開催
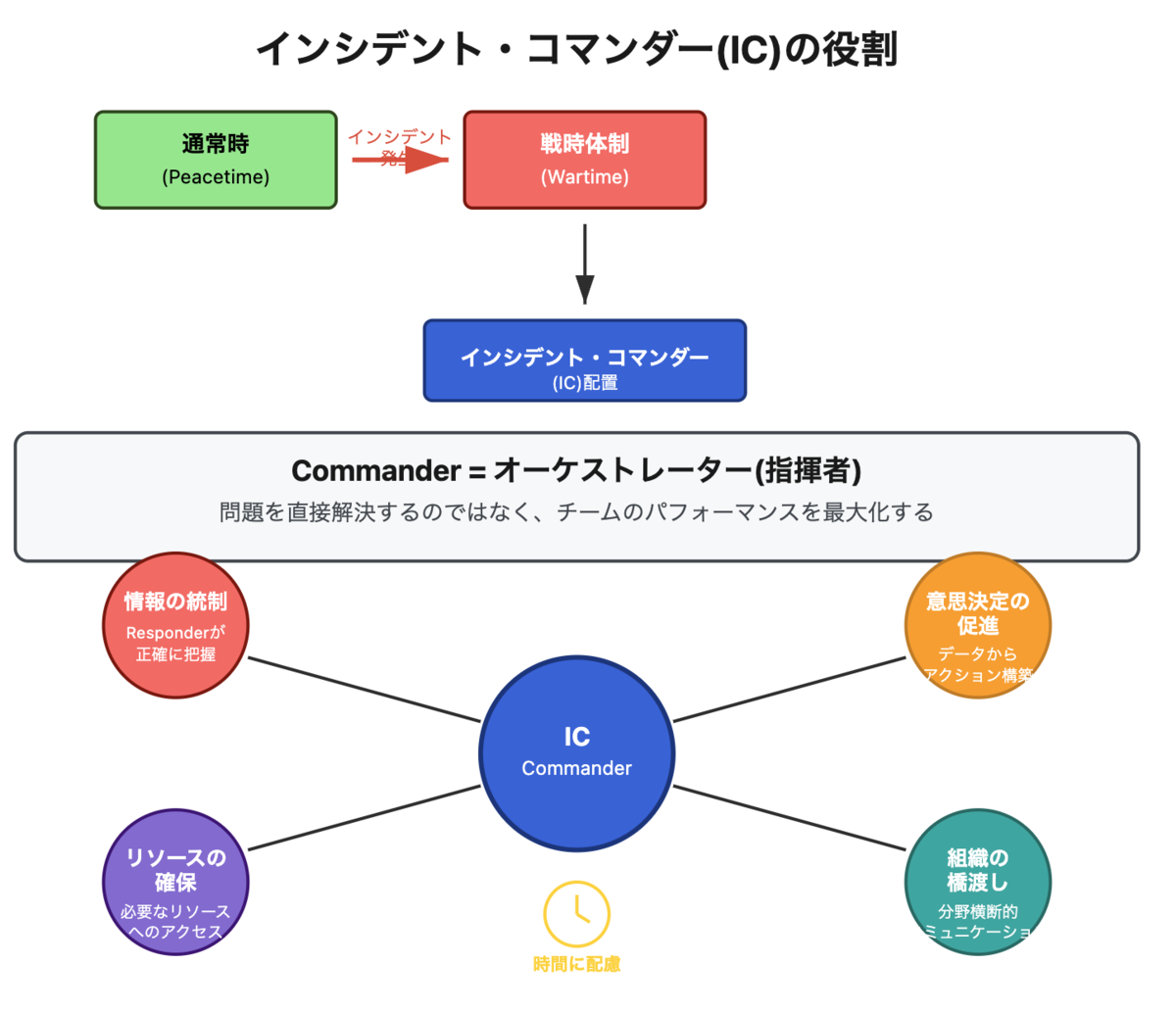
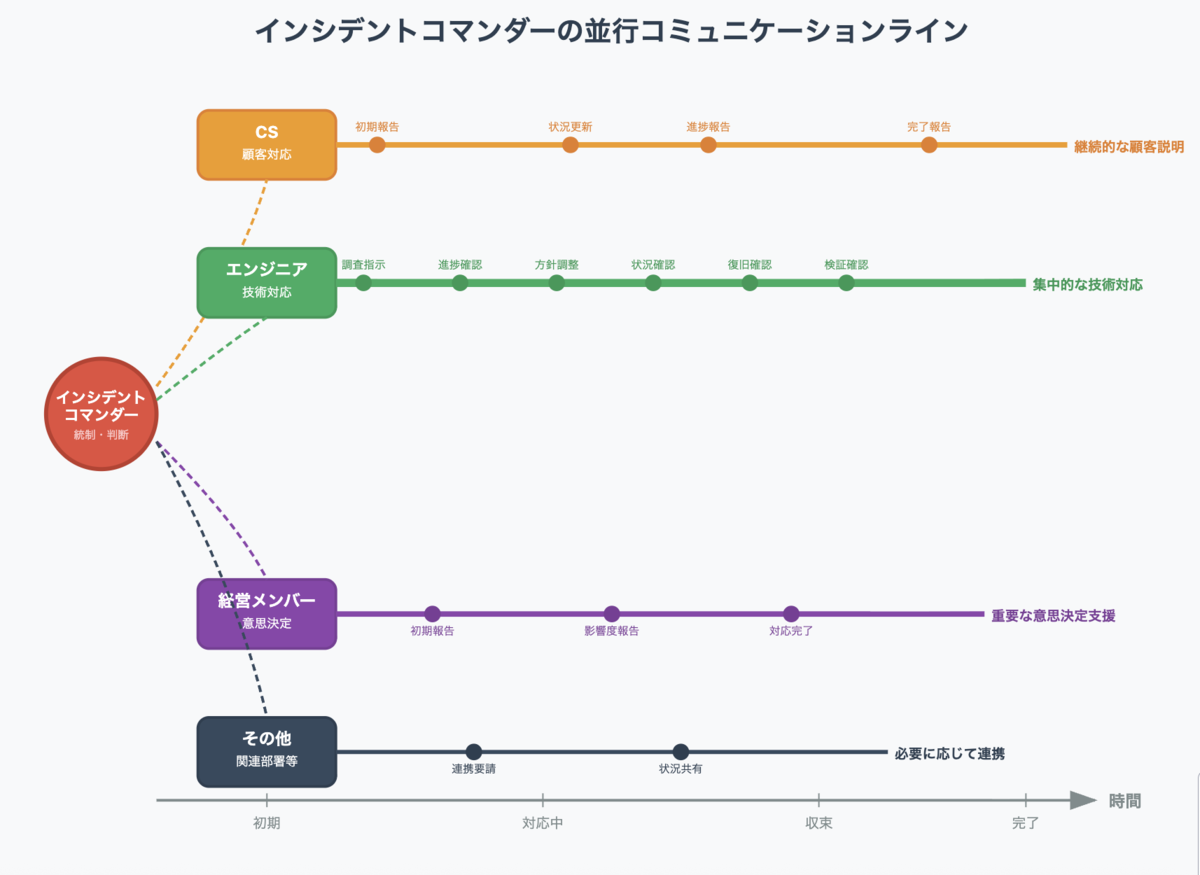
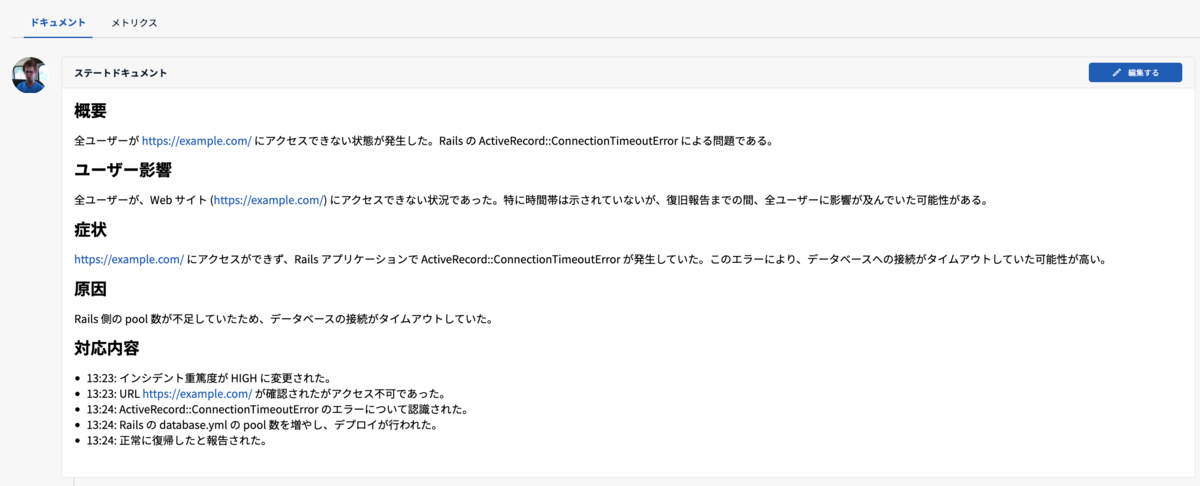
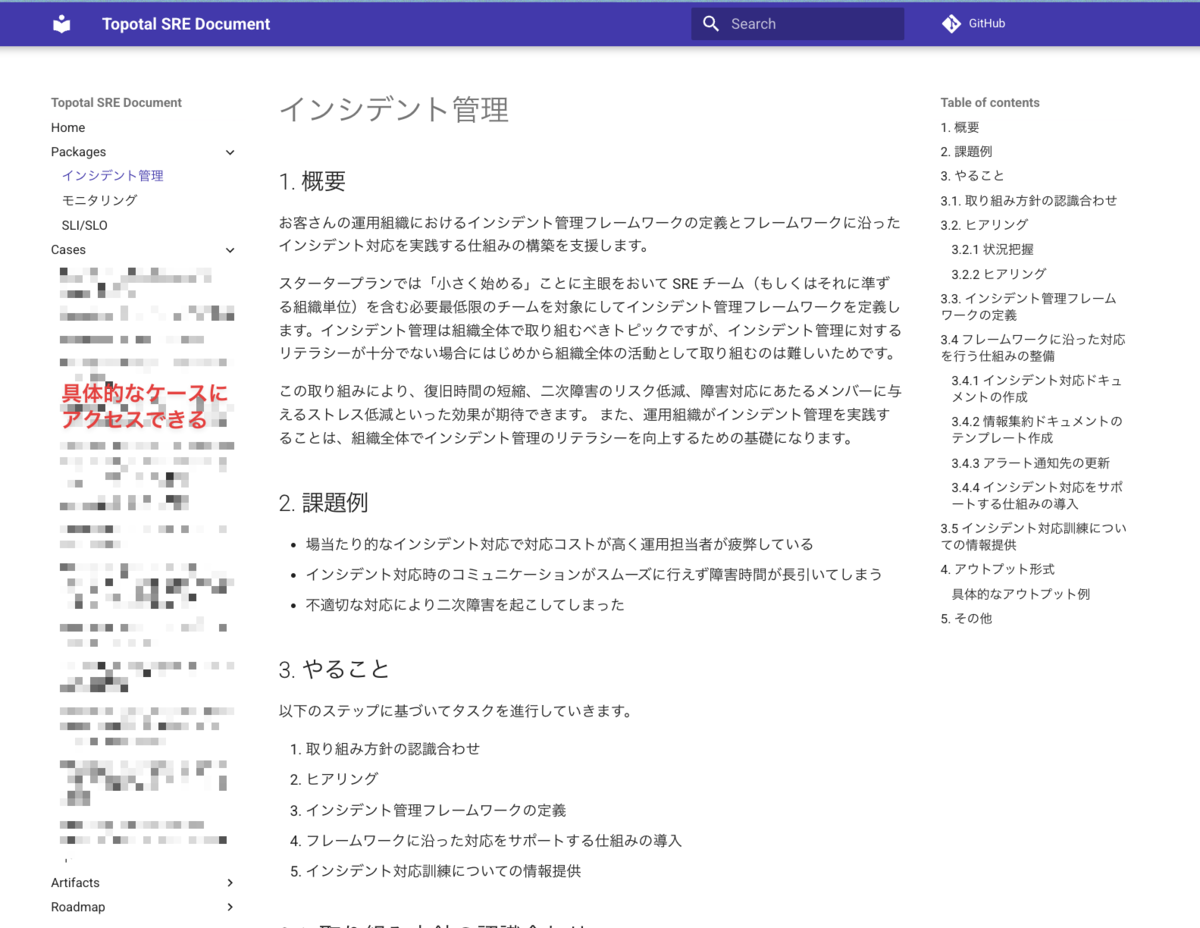
ノウハウを自動的に収集してドキュメント化される基盤(Topotal SRE Document)
Waroomのドッグフーディング <会(ゆるふわ)
Topotal SRE Document
実際にメンバーが経験した技術的な内容にアクセスできる環境は今まで在籍した組織でも整っていないことが多く、この仕組みは特に印象的でした。
20%ルール: 毎週金曜は自社改善デー
毎週金曜日は、メンバー全員が自社の改善に時間を当てています。
Topotal社員のほとんどがSREで構成されていることから、社内のToilには敏感です。もちろんソフトウェアによって解決すべく、このような日が設けられています。
スタートアップとして継続的に改善・構築する必要があるフローは多くありますが、そうした活動をこの日に実施しています:
Software Engineering - 業務プロセスの自動化。社内業務用のCLI 改善などもPlatform Engineering - Topotal社内の基盤改善(k8s やTerraformのメンテナンス、クラウド 基盤のコスト管理など)SRE Advocacy - ブログ(社内・社外問わず)、登壇、コミュニティ活動、勉強会の開催など
これらの活動は、Squad単位(共通の目的を持ったグループ)で行っています。
私はもともと外部発信が得意なので、まずはSRE Advocacyに参加しています。
珍しくなったフルリモートワークの実際
Topotalはフルリモートワークを採用しており、私は個人的な事情で出社が極力必要のない職場を探していたため、この点でマッチしました*1 。
福利厚生として提供されるリモートワーク手当(毎月1万円分のお菓子、炭酸水、備品など)も実用的でありがたく感じています。
「そんなこと言って〜、いつか出社しようっていう話が出るんじゃないの〜?」と懐疑的になる私。
times芸人は今日も元気ですね
弊社には出社すべきオフィスがありませんので、安心してください。
コミュニケーションは基本的にSlackかGather
オフィスがないため、メンバーは基本的にSlackかGatherというバーチャルオフィスで話をしています。
バーチャルオフィスにあまり明るくはなかったのですが、操作は案外簡単です。
バーチャルオフィス Gather
会議の時間になると、大きな部屋にテクテク歩いていくことでそのスペースにいるメンバーと会話できるようになります。それ以外のときは、自分の席(論理)でマイクもカメラもオフにしていることがほとんどです。
事業会社のSREだった私から見た、SRE as a Serviceが持つ可能性
さてここからは私が所属している事業の話になります。
SRE as a Serviceとは『サービスの価値を最大限に引き出すためのエンジニアリングを提供するサービス』です。
自社サービスのSREとは大きく異なり、私たちはお客様のサービスに対して活動します。これまでずっと自社サービスのSREとしてやってきたため、Topotalがどのような支援活動を行っているのかオンボーディングで詳しく学びました。
実際にSRE as a Serviceをご利用いただいた企業の方々の声も参考になります:
前職の私は、非常に多くのプロダクトチームを抱える事業会社であったため、別のチームの支援に参加すると全く違う文脈とルールで支援していました。まるで同じ会社とは思えないほどです。むしろそれが、SRE as a Serviceという事業に貢献できるかもと思ったきっかけです。
Topotalのように多くのお客様の支援ができる場所にいることで、業界全体の信頼性工学に貢献できると思っています。
SRE as a Serviceのビジョン
TopotalのSRE as a Serviceが目指す将来像は、私が常々考えていた世界観に似ていました。
Topotal の考える "SRE as a Service" の将来像は、2019 年の SRECon EMEA にあった発表の SRE in the Third Age や、2020 年の Grafana のブログの What does the future hold for Site Reliability Engineering? に登場する "SRE as a Service" のように、向き合う先を支援先の SRE チームからどんどん広げ、SRE の考え方をビジネス自体に紐づかせ、組織内のほとんどのエンジニアが SRE のプラク ティスを活かしたツールやサービスを享受し、それぞれの開発チームが自律的に信頼性のコントロール ができるような組織を作ることをより支援できるような形にしたい
昨今のSREは多様化しており、その中でもEnabling SRE*2 という分類があります。SRE as a Serviceは、この形式に最も近いのではないかと考えています*3 。自社内でEnabling活動をするか、TopotalがEnabling活動をするかの違いはあれど、信頼性工学という文化を組織にインストールする方向性は私の理想とするSREと一致していました。
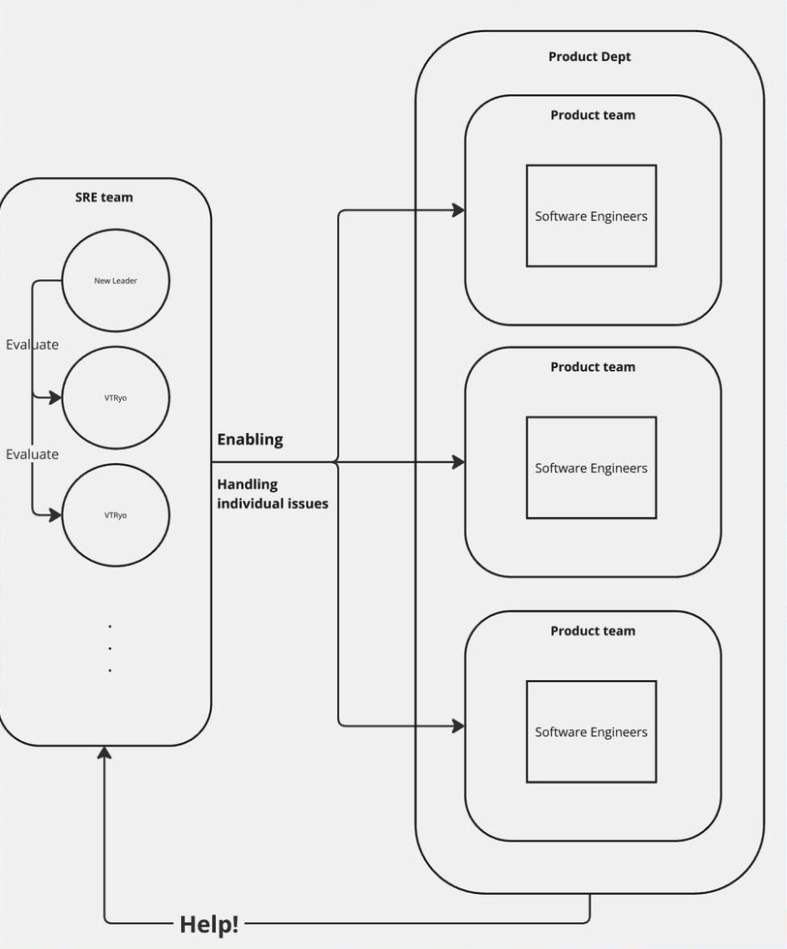
VTRyoが事業会社でEnabling SREをしていたときの組織構図
このような世界観であるため、あるフェーズまで来たらSRE as a Serviceを必要としなくなるフェーズが訪れると思います。しかし、それこそがSRE as a Serviceのひとつの成功とも言えるでしょう。そして私は、その世界を実際に見てみたいと思っています。
SREは職種ではない。だからこそSRE活動を組織に浸透させていく
SREという言葉は割とバズワード です。SREがほしい……! という多くのお客様に弊社は支えられています。しかし支援なしにサービス運用が可能になることも、私たちにとってもひとつの成功であります。
世界で初めてのSREとしての役割を果たしたとされるマーガレット・ハミルトン 氏が活躍した当時、ソフトウェアエンジニアリングという言葉もありませんでした。
それでも彼女の生き方は現代のSRE活動そのものだった*4 のですから、私たちも自分がSREであるかどうかは関係ありません。
wired.jp
SREを自認していなくても、「このサービスはユーザの目的を果たせるか」について考え抜いている間は、その役割を果たしています。
SREは職種ではなく、生き様なのです。
おまけ: CEOもCTOもSREの会社あるある
インフラに関する問題があっても気づかないうちに修正されてました。
こういうのってたいていSREチームに連絡が来るのが常ですけど、よく考えたら私たち全員SREでした。ガハハ。
ドメイン 転送設定が解決されている様子
TopotalではSRE as a Serviceとして業界の信頼性に貢献したいソフトウェアエンジニアを募集しています
現役SREのCEOとのカジュアル面談は、なんといつでもこちらから応募できます!!!!
Topotal 採用情報 -> カジュアル面談はこちら! の部分まで下にスクロールする